Deployment
ML模型部署和预测系统
-
部署ML模型困难,存在几个常见误区:
- 误区一:认为只需要部署一两个模型,而实际上可能需要部署上百个。
- 误区二:认为模型性能不会变化,但实际上会因为数据分布的变化等因素导致性能下降。
- 误区三:认为不需要经常更新模型,但更新越快,效果可能越好。
- 误区四:许多ML工程师认为不需考虑规模问题,但即使是小公司也需要考虑。
-
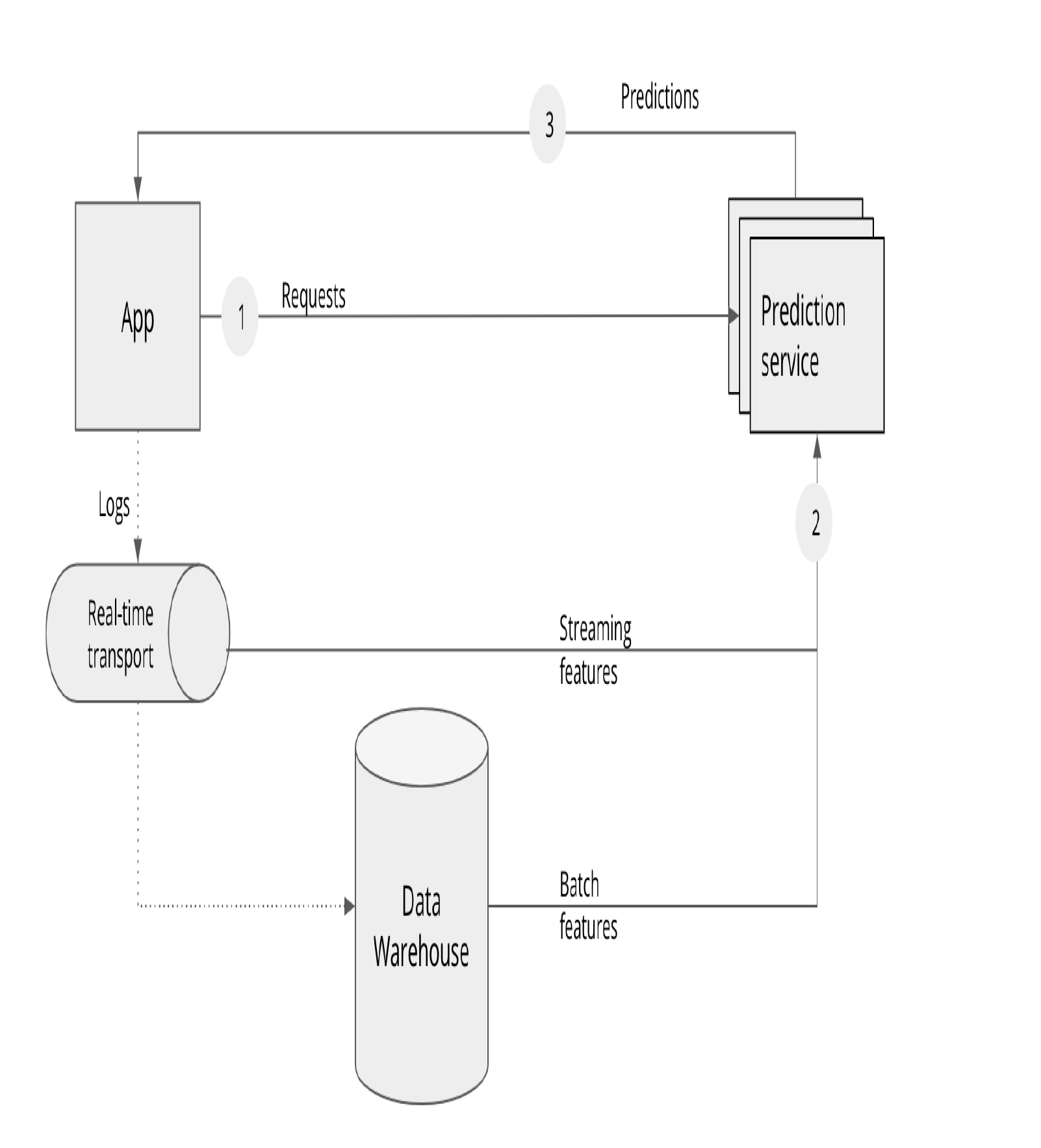
预测方式分为两种:
- 批量预测(Batch Prediction):服务从数据仓库接收批量特征进行预测,应用程序获取预先计算的结果。
- 在线预测(Online Prediction):应用直接向预测服务请求结果,服务实时更新特征。
-
流式在线预测:应用将日志作为流特征发送到预测服务,数据仓库也会提供批量特征。
Batch Prediction 与 Online Prediction 的区别
- 如果预测时间过长,可以使用预先计算(pre-computed)。
- 预先计算可能导致模型对用户变化的反应不够快速。
- 在线ML系统需要同时处理流式特征和批处理特征。
模型压缩
目的是减少延迟,方法包括:
- 低秩分解(Low Rank Factorization):通过压缩内部过滤器减少模型大小。
- 知识蒸馏(Knowledge Distillation):训练一个小型学生模型模仿大模型的输出。
- 剪枝(Pruning):移除神经网络中不必要的部分。
- 量化(Quantization):将权重从32位降低到8位以减少内存使用,可能会影响性能。
补充
- 在线预测和批量预测选择取决于应用场景的具体需求和预测时间敏感度。
- 模型优化和压缩技术是提高部署效率和性能的关键。
- 随着技术发展,新的优化方法持续出现,跟踪最新研究对于MLOps实践至关重要。