tool
MRKL
MRKL(Karpas 等人,2022 年)是 "模块化推理、知识和语言 "的简称,是一种用于自主代理的神经符号架构。建议 MRKL 系统包含一系列 "专家 "模块,而通用 LLM 则作为路由器,将查询路由到最合适的专家模块。这些模块可以是神经模块(如深度学习模型),也可以是符号模块(如数学计算器、货币转换器、天气 API)。
HuggingGPT
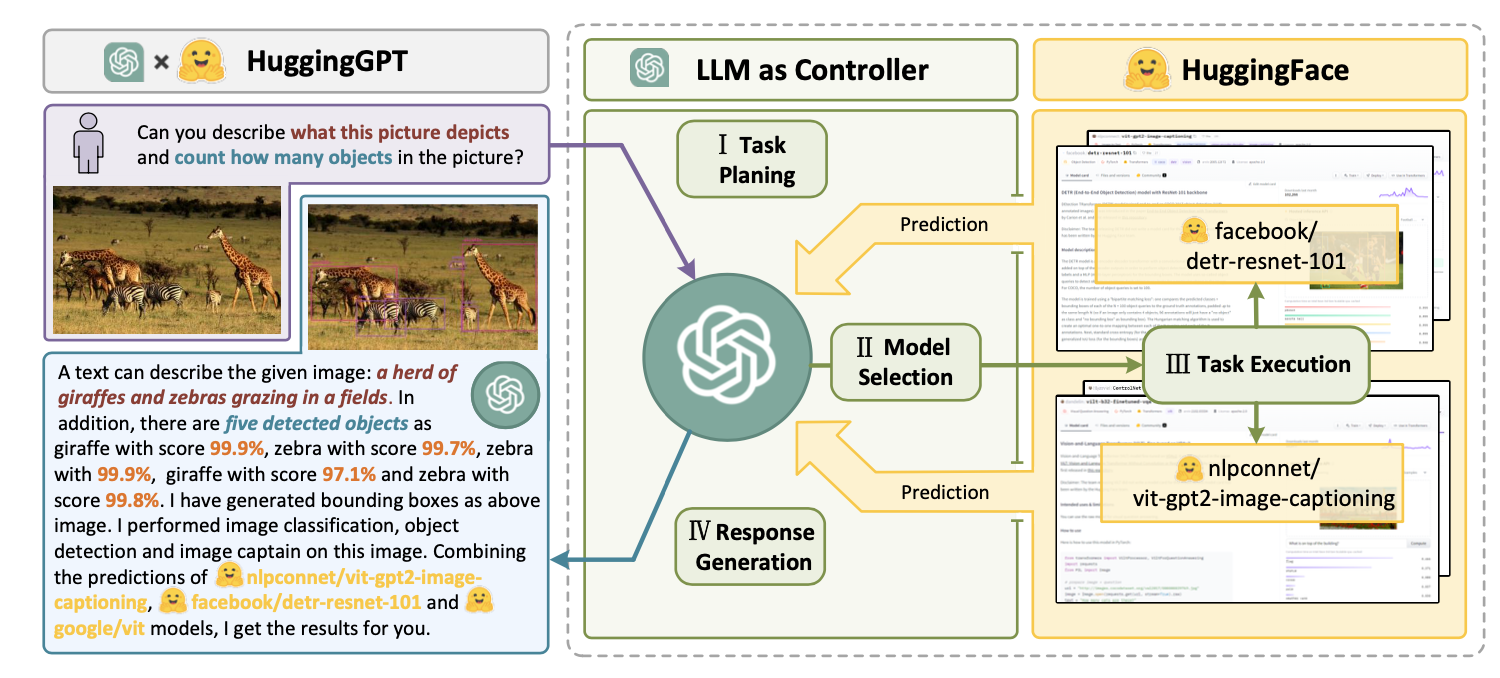
该系统包括 4 个阶段:
(1) 任务规划: LLM 充当大脑,将用户请求解析为多个任务。每个任务都有四个相关属性:任务类型、ID、依赖关系和参数。他们使用少量实例来指导 LLM 进行任务解析和规划。
指令:
人工智能助手可以将用户输入解析为多个任务: {"task":任务,"id":task_id,"dep":依赖关系_task_ids,"args":参数: {"text": 文本,"image": URL, "audio": URL, "video": URL}}]。dep "字段表示生成当前任务所依赖的新资源的前一个任务的 id。特殊标记"-task_id "指的是依赖任务中生成的文本图像、音频和视频,id 为 task_id。必须从以下选项中选择任务: {{可用任务列表 }}}。任务之间存在逻辑关系,请注意它们的顺序。如果无法解析用户输入,则需要回复空 JSON。以下是几个案例供您参考: {{ 演示 }}。聊天记录记录为 {{ 聊天记录 }}。从该聊天历史记录中,您可以找到用户提及的资源路径,以便进行任务规划。
(2) 模型选择: LLM 会将任务分配给专家模型,其中的请求是一道多选题。LLM 会收到一份可供选择的模型列表。由于上下文长度有限,需要进行基于任务类型的过滤。
指令:
给定用户请求和调用命令后,人工智能助手会帮助用户从模型列表中选择一个合适的模型来处理用户请求。人工智能助手仅输出最合适模型的模型 ID。输出必须采用严格的 JSON 格式: "id": "id", "reason": "您选择的详细原因"。我们有一个模型列表供您选择 {{ 候选模型 }}。请从列表中选择一个模型。
(3) 任务执行: 专家模型执行特定任务并记录结果。
指示:
有了输入和推理结果,人工智能助手需要描述过程和结果。前几个阶段可归纳为--用户输入: {{ 用户输入 }}、任务规划: {{ 任务 }}, 模型选择: {{ 模型分配 }}, 任务执行: {{ 预测 }}。首先,您必须直截了当地回答用户的请求。然后以第一人称向用户描述任务过程并展示您的分析和模型推理结果。如果推理结果包含文件路径,必须告诉用户完整的文件路径。
(4) 生成响应: LLM 接收执行结果并向用户提供汇总结果。
要将 HuggingGPT 投入实际应用,需要解决几个难题:(1)需要提高效率,因为 LLM 推理轮和与其他模型的交互都会减慢进程;(2)它依赖于较长的上下文窗口来交流复杂的任务内容;(3)提高 LLM 输出和外部模型服务的稳定性。