Cpu
□ CPU使用率。 这可能是最直接的指标。它描述了每个处理器的整体使用率。如果在一段持续时间内CPU的使用率超过80%,则处理器可能有瓶颈。
□ 用户进程消耗CPU的时间。 描述了CPU花费在用户进程的百分比,包括nice time。较高值的user time通常是有利的,因为,在这种情况下,系统在执行实际的工作。
□ 内核操作消耗CPU的时间。 其描述了CPU花费在内核操作的百分比,包括IRQ和softirq时间。较高和持续的system time值可以指出在网络和驱动程序堆栈中你的瓶颈。一个系统通常应保持花在内核操作上的时间尽可能的少。
□ 等待。 CPU花费在等待(由于一个I/O操作发生等待)上的时间总量,像是阻塞值。一个系统不应该花费太多时间等待(因为I/O操作);否则应该检查各自的I/O子系统性能。
□ CPU空闲时间。 其描述了系统空闲等待任务的CPU百分比。
□ Nice消耗CPU时间。 描述了CPU花费在re-nicing进程(更改进程的执行顺序和优先级)上的时间百分比。
□ 平均负载。 load average不是一个百分比,而是以下总和的滚动平均值:
• 队列中等待处理的进程数。
• 等待不可中断任务被完成的进程数。
也就是说,TASK_RUNNING和TASK_UNINTERRUPTIBLE进程数的总和的平均值。如果进程请求CPU时间而被阻塞(这意味着CPU没有时间处理它们),load average会增加。另一方面,如果每个进程得到直接访问CPU的时间,它们没有在CPU周期丢失,则负载将减小。
□ 可运行的进程。 这个值描述了已经准备好执行的进程数。在一段持续的时间内,这个值不应该超过物理处理器数量的10倍。否则处理器可能是瓶颈。
□ 阻塞的进程。 不被执行的进程数,因为它们要等待I/O操作结束。阻塞的进程数能反映出是否有I/O瓶颈。
□ 上下文切换。 在系统上发生线程之间切换的数量。大量上下文切换如果与大量中断相关,则可能是驱动程序或应用程序出现问题的信号。上下文切换通常是不利的,因为每一次上下文切换都会导致CPU缓存被刷新,但是有些上下文切换是必要的。参考1.1.5节的内容。
□ 中断。 中断包含硬中断与软中断。硬中断对系统性能有更加不利的影响。较高的中断值表明可能有软件瓶颈,可能是在内核中,也可能是一个驱动程序出现瓶颈。记住,中断还包括CPU时钟引起的中断。参考1.1.6节的内容。
uptime
$ uptime
23:51:26 up 21:31, 1 user, load average: 30.02, 26.43, 19.02
This is a quick way to view the load averages, which indicate the number of tasks (processes) wanting to run. On Linux systems, these numbers include processes wanting to run on CPU, as well as processes blocked in uninterruptible I/O (usually disk I/O). This gives a high level idea of resource load (or demand), but can’t be properly understood without other tools. Worth a quick look only. The three numbers are exponentially damped moving sum averages with a 1 minute, 5 minute, and 15 minute constant. The three numbers give us some idea of how load is changing over time. For example, if you’ve been asked to check a problem server, and the 1 minute value is much lower than the 15 minute value, then you might have logged in too late and missed the issue. In the example above, the load averages show a recent increase, hitting 30 for the 1 minute value, compared to 19 for the 15 minute value. That the numbers are this large means a lot of something: probably CPU demand; vmstat or mpstat will confirm, which are commands 3 and 4 in this sequence.
系统平均负载是可运行状态进程或不可中断状态进程的平均数。处在可运行状态的进程要么是正在使用CPU,要么是等待使用CPU。处在不可中断状态的进程正在等待一些I/O访问,例如等待磁盘。平均值有3个时间间隔。因为系统中CPU的数量、平均负载不是规范化的,所以,平均负载为1意味着一个单CPU系统始终是有负载的,在一个4核CPU系统上则意味着它有75%的空闲时间。
平均负载最佳值为1,这意味着每个进程都能立刻访问CPU,并且没有丢失CPU周期。对于单(核)处理器工作站,1或2是可以接受的,而在多处理器服务器上你可能会看到8到10的数字(单核CPU负载是2,4核CPU负载可能是8)。
ps
ps显示有关选择的活跃进程的信息。ps命令提供当前已存在进程的列表。top命令动态显示进程信息,但是ps命令可以以静态方式提供更详细的信息。
ps aux
-A,选择所有进程,与-e相同。
□ -N,选择除满足指定条件以外的所有进程。(否定选择)与--deselect相同。
□ T,选择与该终端相关的所有进程。与不带任何参数的t选项相同。
□ -a,选择除session leader(参见getsid(2))以外的进程和与该终端不相关的所有进程。
□ a,这个选项使得ps列出使用该终端(tty)的所有进程,或当与x选项一起使用时列出所有进程。
□ -d,选择除session leader以外的所有进程。
□ -e,选择所有进程,与-A相同。
□ g,真正所有的进程,甚至是session leader。此选项已经废弃。
□ r,限制只选择正在运行的进程。
□ X,此选项使得ps列出你拥有的所有进程,或当与a选项一起使用时列出所有进程。
□ --deselect,选择除满足指定条件以外的所有进程。(否定选择)与-N相同。
mpstat
mpstat命令用来报告在多处理器服务器上每个可用CPU的相关统计数据(如图2-8所示)
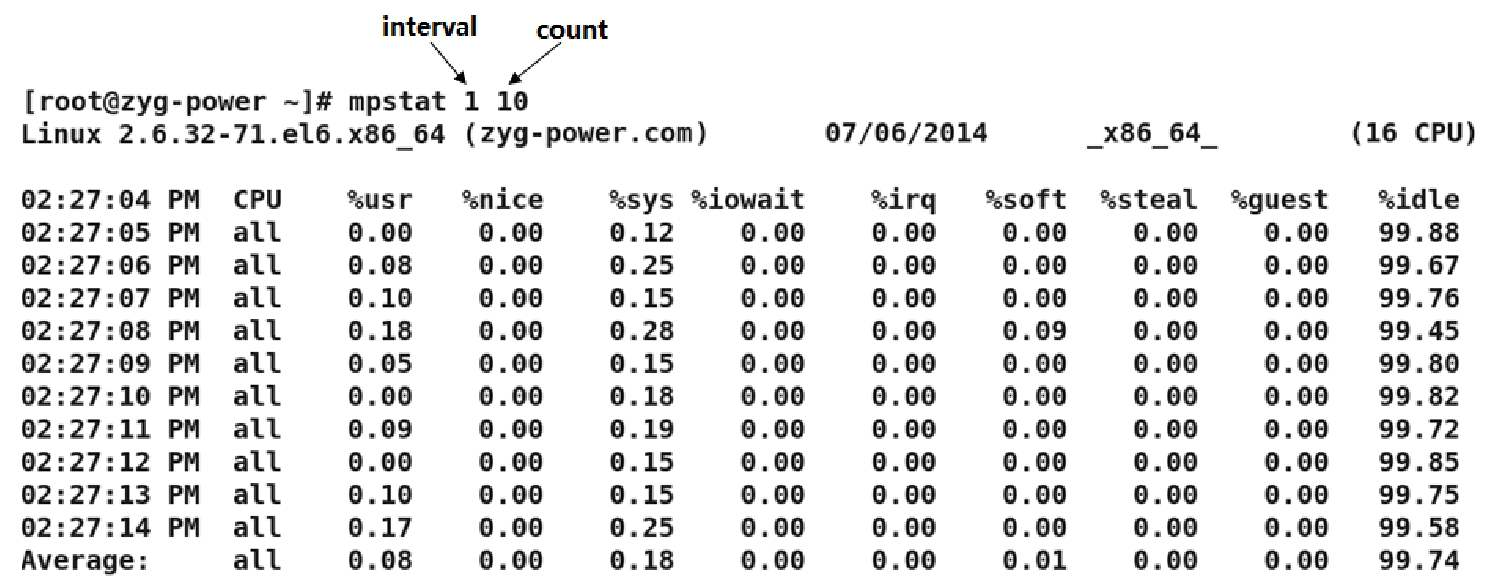
interval参数指定每次报告之间的时间间隔,以秒为单位。值为0(或没有参数)表明报告自系统启动以来的处理器统计数据。count参数如果不设置为0则可以和interval参数结合使用。count的值决定了间隔秒数生成报告的次数。如果只指定interval参数,没有count参数,那么mpstat命令将不断地生成报告。
$ mpstat -P ALL 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:38:49 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
07:38:50 PM all 98.47 0.00 0.75 0.00 0.00 0.00 0.00 0.00 0.00 0.78
07:38:50 PM 0 96.04 0.00 2.97 0.00 0.00 0.00 0.00 0.00 0.00 0.99
07:38:50 PM 1 97.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 2.00
07:38:50 PM 2 98.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00
07:38:50 PM 3 96.97 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.03
[...]
This command prints CPU time breakdowns per CPU, which can be used to check for an imbalance. A single hot CPU can be evidence of a single-threaded application.
strace
strace用来跟踪系统调用和信号。strace是一个很有用的诊断、指导和调试的工具。系统管理员可以很方便地使用它来诊断和解决程序出现的问题,因为可以在不需要重新编译的情况下来跟踪它们。最简单的情况就是使用strace运行指定的命令,直到命令结束。它拦截并记录进程执行的系统调用和进程接收的信号。每个系统调用的名称、参数和返回值都将被显示在标准错误输出中或可以通过-o选项指定到文件。
trace system calls and signals
跟踪的每一行包含系统调用的名称,其次是括号中的参数,还有返回值。下面是cat命令的跟踪例子:
[root@zyg ~]# strace cat/tmp/file1
execve("/bin/cat", ["cat", "/tmp/file1"], [/* 29 vars */]) = 0
brk(0) =0x19f0000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f229ad6b000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=81712, ...}) = 0
mmap(NULL, 81712, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f229ad57000
close(3) =0
open("/lib64/libc.so.6", O_RDONLY) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0000\356\341\2426\0\0\0"..., 832)= 832
fstat(3, {st_mode=S_IFREG|0755, st_size=1926800, ...}) = 0
mmap(0x36a2e00000, 3750152, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0)= 0x36a2e00000
mprotect(0x36a2f8b000, 2093056, PROT_NONE) = 0
mmap(0x36a318a000, 20480, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x18a000) = 0x36a318a000
mmap(0x36a318f000, 18696, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x36a318f000
close(3) =0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f229ad56000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f229ad55000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f229ad54000
arch_prctl(ARCH_SET_FS, 0x7f229ad55700) = 0
mprotect(0x36a318a000, 16384, PROT_READ) = 0
mprotect(0x36a281f000, 4096, PROT_READ) = 0
munmap(0x7f229ad57000, 81712) =0
brk(0) =0x19f0000
brk(0x1a11000) =0x1a11000
open("/usr/lib/locale/locale-archive", O_RDONLY) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=99158576, ...}) = 0
mmap(NULL, 99158576, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f2294ec3000
close(3) =0
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 2), ...}) = 0
open("/tmp/file1", O_RDONLY) =3
fstat(3, {st_mode=S_IFREG|0644, st_size=4, ...}) = 0
read(3, "111\n", 32768) =4
write(1, "111\n", 4111
) =4
read(3, "", 32768) =0
close(3) =0
close(1) =0
close(2) =0
exit_group(0) =?
还有另一个有趣的用途。此命令还可以报告执行一个命令每个系统调用在内核中消耗时间的统计,使用-c选项:
[root@zyg ~]# strace -c cat /tmp/file1
111
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
60.82 0.000863 863 1 execve
14.87 0.000211 35 6 close
12.40 0.000176 20 9 mmap
11.91 0.000169 42 4 open
0.00 0.000000 0 3 read
0.00 0.000000 0 1 write
0.00 0.000000 0 5 fstat
0.00 0.000000 0 3 mprotect
0.00 0.000000 0 1 munmap
0.00 0.000000 0 3 brk
0.00 0.000000 0 1 1 access
0.00 0.000000 0 1 arch_prctl
------ ----------- ----------- --------- --------- ----------------
ltrace
ltrace是一个库调用跟踪程序,其可以通过ltrace简单运行指定命令直到它退出。它截取和记录执行进程所进行的动态库调用,和进程接收的信号。它也可以截取和显示程序执行的系统调用。它的使用与strace非常类似。ltrace显示调用函数的参数和系统调用。要确定每个函数有什么样的参数,它需要函数原型的外部声明。这些都被存储在被称为原型库的文件中,这些文件的语法细节参考ltrace.conf(5)。参见PROTOTYPE LIBRARY DISCOVERY章节学习ltrace如何找到原型库。
how
第一步是确认系统性能问题是CPU引起的,而不是其他子系统。如果处理器是服务器的瓶颈,那么采取一些行动来提高性能,其中包括:
□ 使用ps -ef命令来确认后台没有运行不必要的程序。如果发现这样的程序,停止它们并使用cron来安排它们在非高峰时段运行。
□ 使用top识别非关键性CPU密集型程序,并使用renice修改它们的优先级。 □ 根据正在运行的应用程序,可能更大的扩展(更大的CPU)要比更多的扩展(更多CPU)好。这要取决于你的应用程序是否都被设计为有效地利用更多CPU。比如,一个单线程的应用程序通过一个更快的CPU可以更好地扩展,而不是更多的CPU。
□ 通常的选项包括,确保使用最新的驱动程序和固件,因为这可能影响它们在CPU上的负载。