Zippydb
zippydb
fb internal distributed key-value databse
single node based on rockdb
arch
ZippyDB servers can be mapped to the roles in the Multi-Paxos protocol as follows:
Primary server = proposer/leader + acceptor + learner Secondary server = acceptor + learner Follower server = learner (An ordinary ZippyDB user may safely skip the details of the mapping above, as it is only intended to map terminology for readers who are familiar with Paxos.)
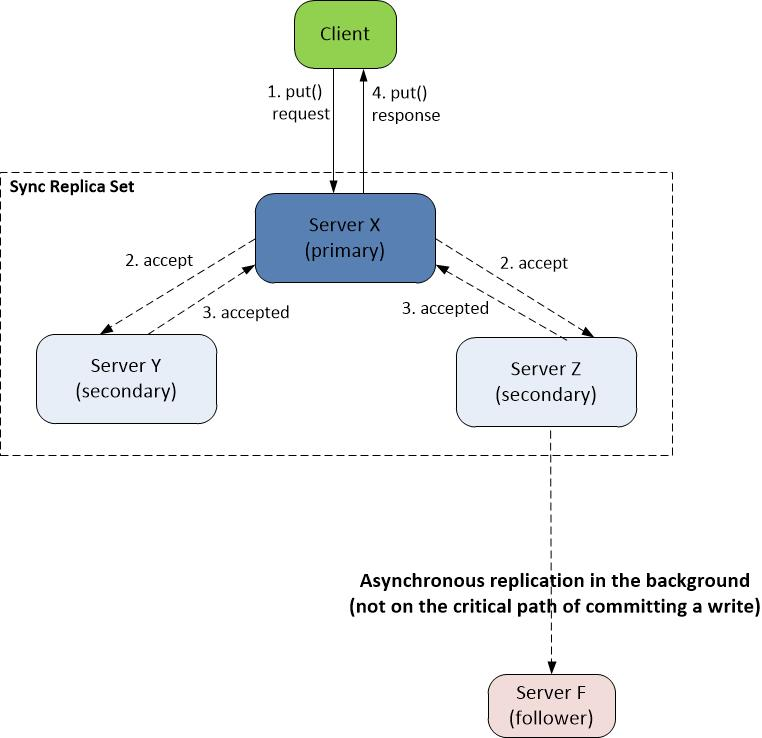
write
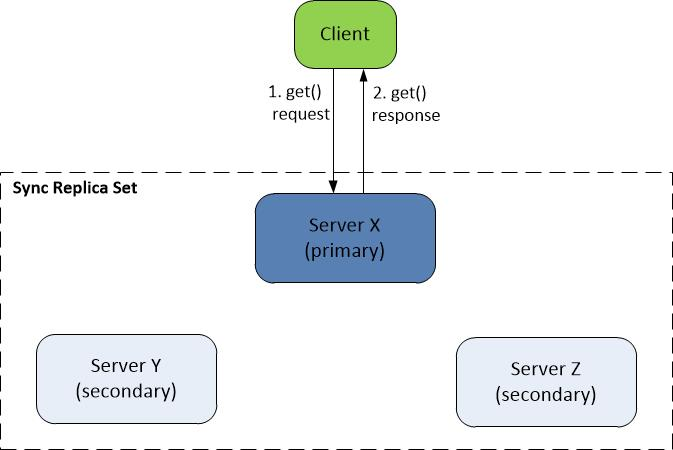
read
primary failover
When the primary fails, Zeus detects the failure through lost heartbeats and notifies ShardManager. ShardManager chooses a most appropriate secondary and sends it a message to convert it into a new primary.
Specifically in this example, it is possible that, right before server X crashed, server X and server Y worked together to accept a write and server X has already sent the "write-success" response back to the client, but that write has not yet reached server Z. This is because server X and server Y form a majority and hence can accept a write without waiting for the "accepted" confirmation from server Z. Actually, server Z may never get the "accept" notification for this write from server X before server X crashed, e.g., due to slow network between server X and server Z. In this case, after server Z becomes the new primary, it needs to contact server Y to recover the missing write. The prepare phase of the Paxos protocol guarantees that the new primary will correctly discover all those missing writes, so long as only a minority of the replicas have failed. After bringing its local replica up-to-date, the new primary (server Z in this example) starts to handle reads and writes as normal. As shown in the figure below, the write path executes the following steps in sequence:
- When the client wants to send a new "Put()" request, the ServiceRouter library linked into the client notices that ShardManager has changed the shard's primary assignment, and automatically routes the request to the new primary (server Z).
- Server Z asks both server X and server Y to "accept" the write.
- Server Z gets the "accepted" confirmation from server Y, but gets no confirmation from server X.
- Since server Z collects a majority votes for the write (one from itself and another from server Y), server Z decides to commit the write and sends a "write-success" response back to the client. Server Z does not wait for server X to recover in order to accept the write. In other words, once server Z becomes the new primary, the failure of server X does not affect the database's availability .
- Server Z sends a "commit" message to server Y to inform server Y that an agreement has been reached on the write. This step is not shown in the figure for brevity.
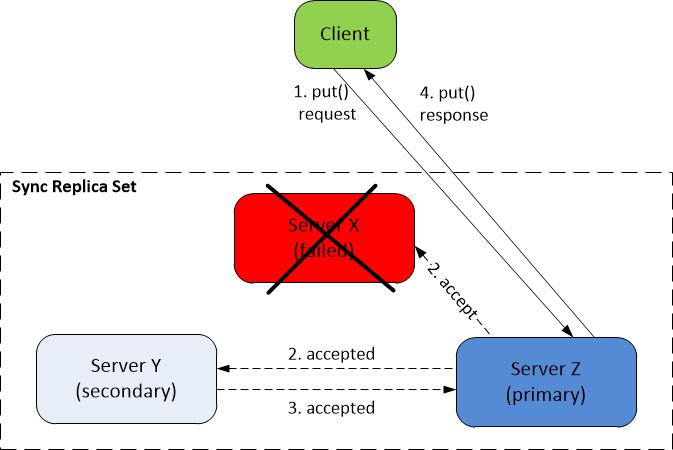
The process of primary fail-over takes about 10 seconds, including the time for Zeus to detect lost heartbeats from the old primary
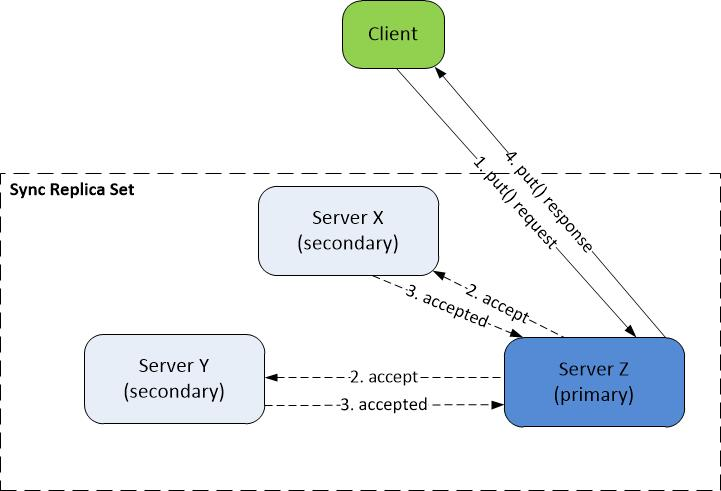
A Failed Replica Rejoins
Server X synchronizes with the new primary (server Z) to bring its local database up-to-date. It then starts to process protocol messages as normal. See the example in the figure below.
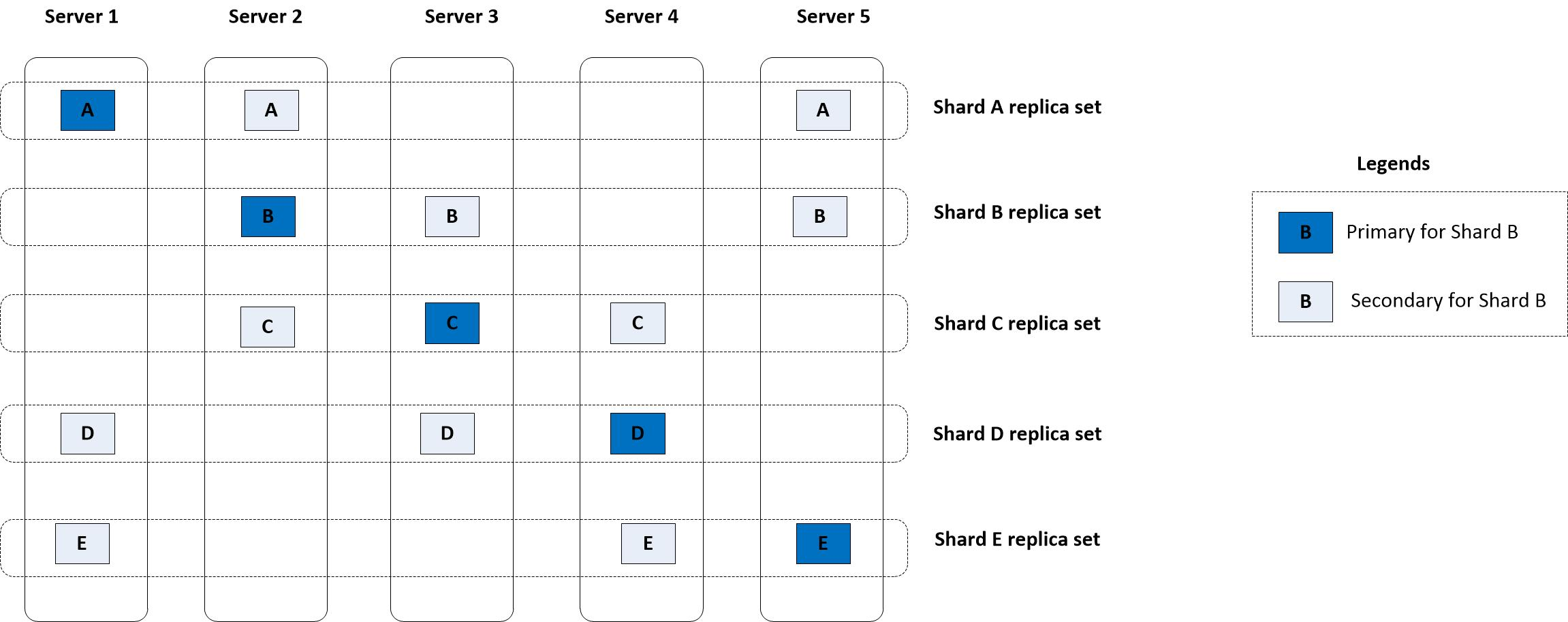
Sharding and Load Balancing
In practice, each server runs a single ZippyDB process that can host multiple shards. In the figure below, each server hosts three shards: a primary for one shard, and two secondaries for two other shards. For example, server 1 hosts shard A's primary, shard D's secondary, and shard E's secondary. The three replicas of shard A are distributed across server 1 (primary), server 2 (secondary), and server 5 (secondary). ShardManager considers multiple factors in shard placement. In this figure, ShardManager places exactly one primary on each server for the purpose of load balancing, because a primary incurs a higher load than a secondary does. ShardManager may also place the different replicas of a shard across different clusters for the purpose of better fault tolerance.
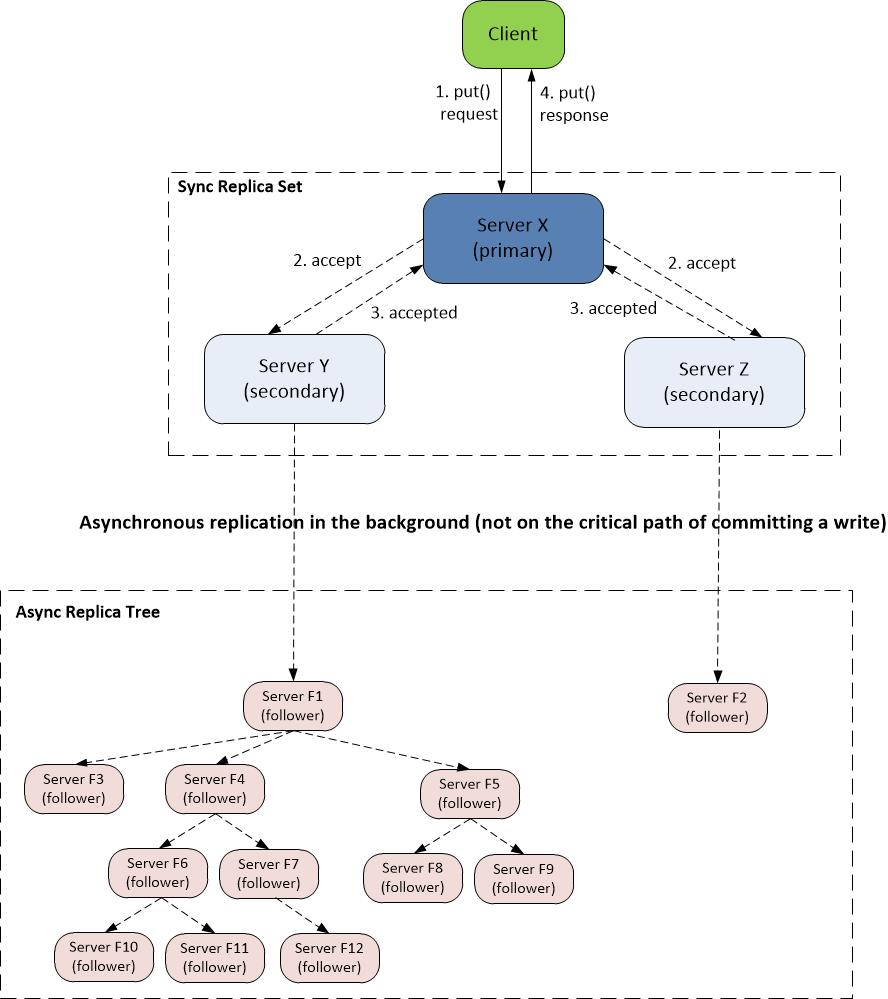
Asynchronous Replication Overview