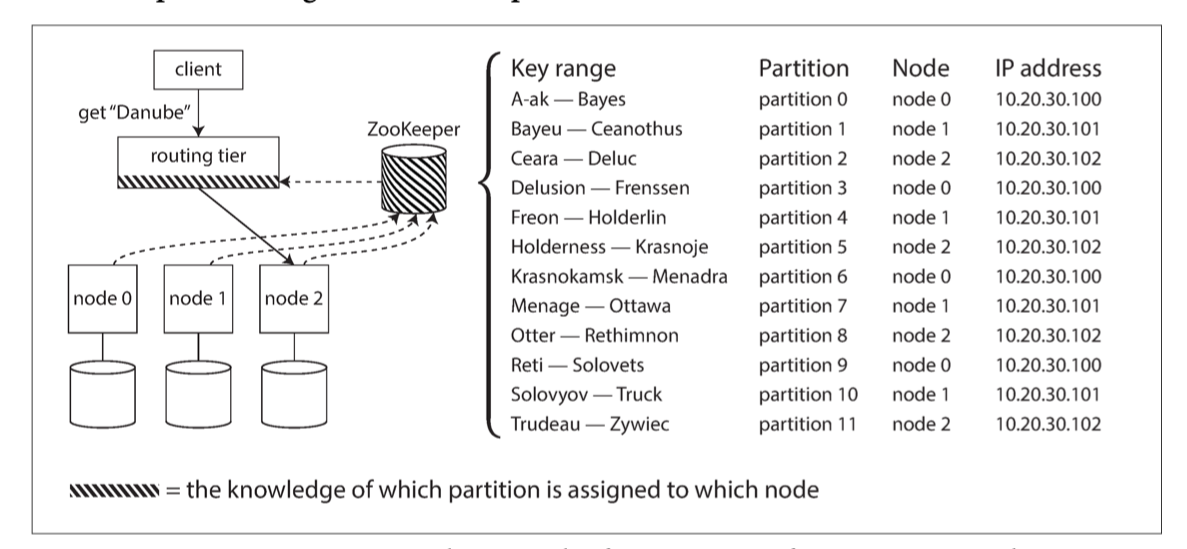
Partition
- NAÏVE TABLE PARTITIONING: Each node stores one and only table.
- HORIZONTAL PARTITIONING: Split a table's tuples into disjoint subsets. Choose column(s) that divides the database equally in terms of size, load, or usage. (Hash Partitioning, Range Partitioning)
Partitioning of Key-Value Data
One way of partitioning is to assign a continuous range of keys (from some mini‐mum to some maximum) to each partition. The partition boundaries might be chosen manually by an administrator, or the data‐base can choose them automatically. Within each partition, we can keep keys in sorted order. This has the advantage that range scans are easy, and you can treat the key as a concatenated index in order to fetch several related records in one query
another way is to use hash of key to partition, reduce the risk of skew and hot spots. by using the hash of the key for partitioning we lose a nice property of key-range partitioning: the ability to do efficient range queries. Keys that were once adjacent are now scattered across all the partitions, so their sort order is lost
secondary index
Rather than each partition having its own secondary index (a local index), we can construct a global index that covers data in all partitions. The advantage of a global (term-partitioned) index over a document-partitioned index is that it can make reads more efficient: rather than doing scatter/gather over all partitions, a client only needs to make a request to the partition containing the term that it wants.
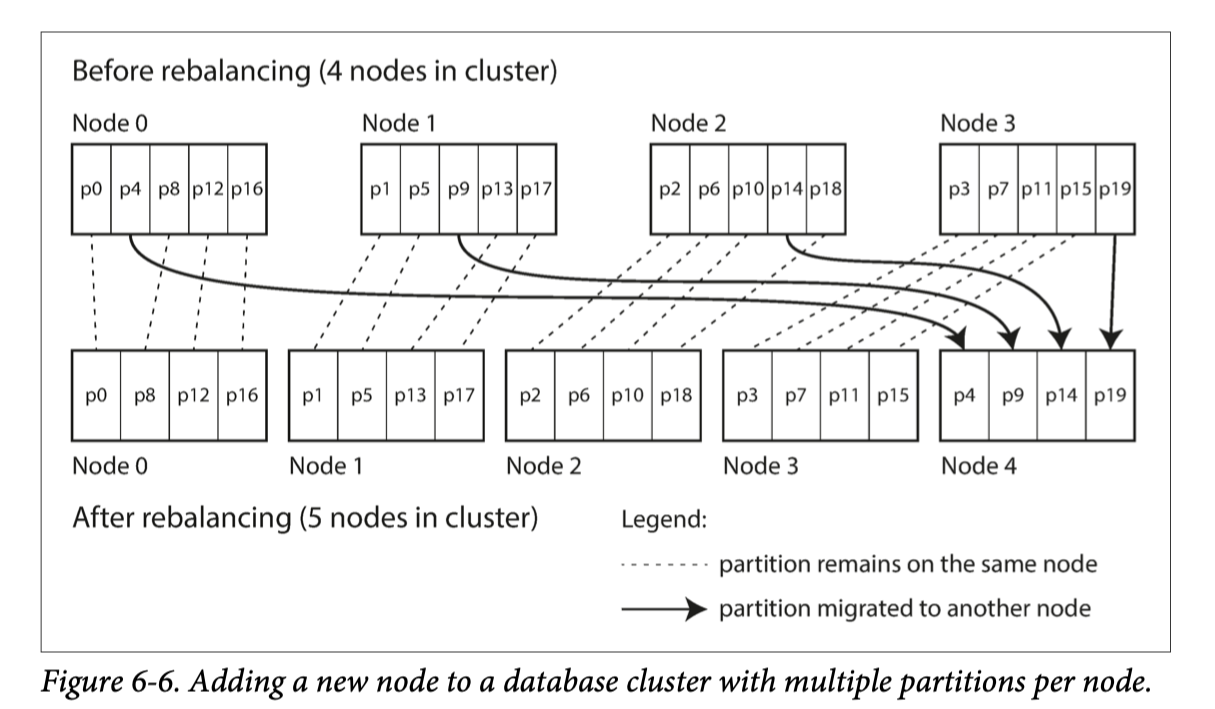
rebalancing
simple solution: create many more partitions than there are nodes, and assign several partitions to each node
routing