Nosql
nosql
NoSQL is a non-relational DMS, that does not require a fixed schema, avoids joins, and is easy to scale.
NoSQL database is used for distributed data stores with humongous data storage needs
NoSQL databases can be document based, key-value pairs, graph databases.
- horizontally scalable (more machines)
- use dynamic schema for unstructured data.
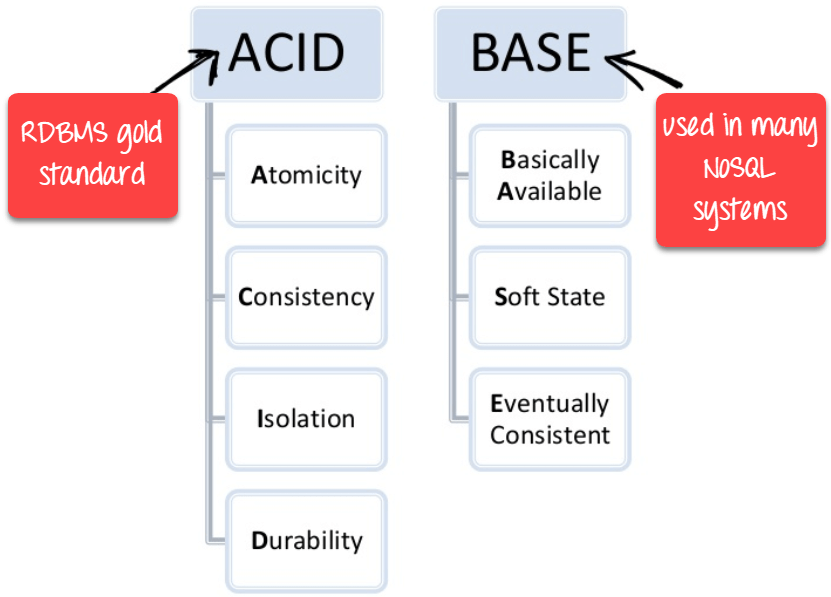
here are several driving forces behind the adoption of NoSQL databases, including:
- A need for greater scalability than relational databases can easily achieve, includ‐ing very large datasets or very high write throughput
- A widespread preference for free and open source software over commercial database products
- Specialized query operations that are not well supported by the relational model
- Frustration with the restrictiveness of relational schemas, and a desire for a more dynamic and expressive data model
bad
- one-to-many structure
- access hard
- hard to keep consistent if many-to-many
- not need join
good
A document is usually stored as a single continuous string, encoded as JSON, XML, or a binary variant thereof (such as MongoDB’s BSON). If your application often needs to access the entire document (for example, to render it on a web page), there is a performance advantage to this storage locality.
Schema flexibility in the document model
cassandra
Setting up Cassandra is quite simple and the maintenance is automatically done. The platform is quite fast even when it is scaled up or a node is added. Cassandra also takes care of re-syncing, balancing or distribution of data. The platform is known to provide high velocity random read writes compared to other NoSQL platforms since it has columnar storage capability and distributed decentralized architecture.
Flexible Sparse & Wide Column requirements talk about capability to increase your columns as and when you need. It is suitable only in those cases where secondary index needs are less, which means you have it absolutely de-normalized. In other words all information is available to serve a specific query and does not go across multiple tables to get server specific client query.
It is important to know that Cassandra is suitable with non-group by kind of models. For applications that have requirement of group-by functionality, Cassandra would not be the right system to choose. This also includes bringing in secondary indexes, which will result into overall performance of system going down.
very high velocity of random read & writes & wide column requirements.
与BigTable和其模仿者HBase不同,Cassandra的数据并不存储在分布式文件系统如GFS或HDFS中,而是直接存于本地。与BigTable一样,Cassandra也是日志型数据库,即把新写入的数据存储在内存的Memtable中并通过磁盘中的CommitLog来做持久化,内存填满后将数据按照key的顺序写进一个只读文件SSTable中,每次读取数据时将所有SSTable和内存中的数据进行查找和合并。这种系统的特点是写入比读取更快,因为写入一条数据是顺序计入commit log中,不需要随机读取磁盘以及搜索。
集群没有master的概念,所有节点都是同样的角色,彻底避免了整个系统的单点问题导致的不稳定性,集群间的状态同步通过Gossip协议来进行P2P的通信。每个节点都把数据存储在本地,每个节点都接受来自客户端的请求。每次客户端随机选择集群中的一个节点来请求数据,对应接受请求的节点将对应的key在一致性哈希的环上定位是哪些节点应该存储这个数据,将请求转发到对应的节点上,并将对应若干节点的查询反馈返回给客户端。
在一致性、可用性和分区耐受能力(CAP)的折衷问题上,Cassandra和Dynamo一样比较灵活。Cassandra的每个keyspace可配置一行数据会写入多少个节点(设这个数为N),来保证数据不因为机器宕机或磁盘损坏而丢失数据,即保证了CAP中的P。用户在读写数据时可以指定要求成功写到多少个节点才算写入成功(设为W),以及成功从多少个节点读取到了数据才算成功(设为R)。可推理得出,当W+R>N时,读到的数据一定是上一次写入的,即维护了强一致性,确保了CAP中的C。当W+R<=N时,数据是最终一致性因为存在一段时间可能读到的并不是最新版的数据。当W=N或R=N时,意味着系统只要有一个节点无响应或宕机,就有一部分数据无法成功写或者读,即失去了CAP中的可用性A。因此,大多数系统中,都将N设为3,W和R设为QUORUM,即“过半数”——在N为3时QUORUM是2。
partition
- ring techonology.
- hash round off
- hash value used assign key to nodes
replication
- rack unware: data at next N-1
- rack aware: use zookeeper to choose a leader to tell nodes the range they replica for
- datacenter aware: datacenter level
gossip protocol
- Periodic, Pairwise, inter-node communication.
- Random selection of peers.
- Example – Node A wish to search for pattern in data
- Round 1 – Node A searches locally and then gossips with node B.
- Round 2 – Node A,B gossips with C and D.
- Round 3 – Nodes A,B,C and D gossips with 4 other nodes ......
- Round by round doubling makes protocol very robust.
Local Persistence
- Write operations happens in 2 steps
- Write to commit log in local disk of the node
- Update in-memory data structure.
- Read operation
- Looks up in-memory ds first before looking up files on disk.
- Uses Bloom- Filter (summarization of keys in file store in memory) to avoid looking up files that do not contain the key.
HBase
HBase是Apache Hadoop项目的一个子项目,是Google BigTable的一个克隆,与Cassandra一样,它们都使用了BigTable的列族式的数据模型,但是:
Cassandra只有一种节点,而HBase有多种不同角色,除了处理读写请求的region server之外,其架构在一套完整的HDFS分布式文件系统之上,并需要ZooKeeper来同步集群状态,部署上Cassandra更简单。 Cassandra的数据一致性策略是可配置的,可选择是强一致性还是性能更高的最终一致性;而HBase总是强一致性的。 Cassandra通过一致性哈希来决定一行数据存储在哪些节点,靠概率上的平均来实现负载均衡;而HBase每段数据(region)只有一个节点负责处理,由master来动态分配一个region是否大到需要拆分成两个,同时会将过热的节点上的一些region动态的分配给负载较低的节点,因此实现动态的负载均衡。 因为每个region同时只能有一个节点处理,一旦这个节点无响应,在系统将这个节点的所有region转移到其他节点之前这些数据便无法读写,加上master也只有一个节点,备用master的恢复也需要时间,因此HBase在一定程度上有单点问题;而Cassandra无单点问题。 Cassandra的读写性能优于HBase[17]。