Filesystem
file system
- what: a file is a unit of data organized by user. a service responsible for managing files
- why: key is robust and high-throughput
- how: name, access, physical allocation, security and protection, resource administration.
NFS and AFS
- NFS has no client caching, cliented cached anyway, central system
- AFS is stateful server and has cache protocol. called to have data client there is an update, their cache is invalid. Whole file semantic
- CODA, add replication and added weakly connected mode.
RAIDS and HDFS
Normal disk
- An error-correcting code (ECC) or forward error correction (FEC) code is a process of adding redundant data, or parity data, to a message, such that it can be recovered by a receiver even when a number of errors (up to the capability of the code being used) were introduced, either during the process of transmission, or on storage.
- RAM could cache the data. It will only read data from disks. If there was error, disk will return nothing.
RAIDS
- what:Redundant Array of Independent Disks,combines multiple physical disk drive components into one or more logical units for the purposes of data redundancy, performance improvement, or both.
- why: more rebust, larger volume,higher throughput
- how:
- RAID 0 它將兩个以上的磁盘並联起来,成为一个大容量的磁盘。在存放数据时,分段后分散儲存在这些磁盘中,因為读写時都可以并行處理,所以在所有的级别中,RAID 0的速度是最快的。no redundancy,just split into serveral disks
- RAID 1: mirroring,disk0=disk1,在一些多线程操作系统中能有很好的读取速度,replication,理論上读取速度等於硬盘數量的倍數,与RAID 0相同
- RAID 2:这是RAID 0的改良版,以汉明码(Hamming Code)的方式将数据进行编码后分割为独立的位元,并将数据分别写入硬盘中。因为在数据中加入了错误修正码(ECC,Error Correction Code),所以数据整体的容量会比原始数据大一些. log2. Have disks save error correction code for each partition.
- RAID3: a disk save parity. 採用Bit-interleaving(数据交错儲存)技術,它需要通过编码再将数据位元分割後分别存在硬盘中,而将同位元检查後单独存在一个硬盘中,但由于数据内的位元分散在不同的硬盘上,因此就算要读取一小段数据资料都可能需要所有的硬盘进行工作,所以这种规格比较适于读取大量数据时使用。
- RAID4:它与RAID 3不同的是它在分割时是以block为单位分别存在硬盘中
- RAID5:RAID Level 5是一种储存性能、数据安全和存储成本兼顾的存储解决方案。它使用的是Disk Striping(硬盘分割)技术。RAID 5至少需要三块硬碟,RAID 5不是对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储於不同的磁盘上。当RAID5的一个磁盘数据发生损坏後,可以利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。

- RAID6:与RAID 5相比,RAID 6增加第二个独立的奇偶校验信息块
- RAID10 = RAID0+RAID1
LUSTRE
- what:a type of parallel distributed file system, generally used for large-scale cluster computing
- why: used for supercomputing, network RAID
- how:
- Files are broken into objects, very similar to stripes. These stripes can be stored by different nodes.
- One or more metadata servers (MDS) nodes that has one or more metadata target (MDT) devices per Lustre filesystem that stores namespace metadata, such as filenames, directories, access permissions, and file layout(different access pattern,data is small)
- One or more object storage server (OSS) nodes that store file data on one or more object storage target (OST) devices.(enable either OSS talk to either OST)
- Client(s) that access and use the data. Lustre presents all clients with a unified namespace for all of the files and data in the filesystem
- high performance network to transfer data and manage network to manage data
MOGILEFS
- what:distributed filesystem
- why:no editing, whole file,fast deliver to clients
- how:
- replicated storage:it replicates objects across servers. The number of replicas is associated with the class of the file, so, for example, photos might have three replicas, each, but thumbnails, which can be recreated from the original photos, might only have one replica of each. this reduces the cost of the storage by allowing less expensive components.
- http+MySQL:MogileFS uses HTTP to server objects from each replica, as opposed to a home-grown protocol, for portability. For the same reason, it keeps its metadata in a standard MySQL database.
- portable
- no hierachy: it maintains simple namespaces, rather than directory trees, is much simpler and more efficient than a full-blown directory system
HDFS
assumption
- failure is a norm, especially on datanode. It is used to handle streaming data.
- emphasis is on throughput not on latency
- large data sets
- simple coherency model: write once and read many
- moving computation is cheaper than moving data
- The good news is that it won't be edited in place. We'll just be collecting it, adding to it.
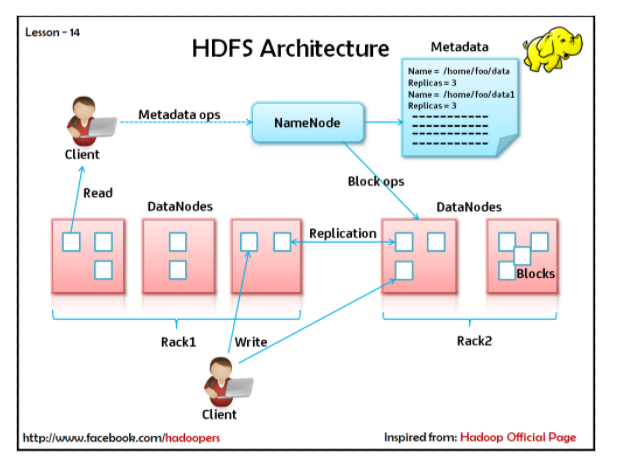
namenode
- what: master-slave architecture
- why: manage namespace as coordinator, only 1
- how: block to DataNodes mapping
- data never go to namenode
- hierarchical name space: maybe not needed, low overhead
datanode
- manage storage attached to node
- create and delete block, replicate blocks
access mode
- read anywhere
- write only at end(append)
- no edit/random write
replication
- blocks are all same size
- fault tolerance
- namenode managed replication
- pipelining
- When a client is writing data to an HDFS file, its data is first written to a local file as explained in the previous section.
- The first DataNode starts receiving the data in small portions (4 KB), writes each portion to its local repository and transfers that portion to the second DataNode in the list. The second DataNode, in turn starts receiving each portion of the data block, writes that portion to its repository and then flushes that portion to the third DataNode.
- less bandwidth and less hot-spot